개요
- 아래와 같은 소스코드 파악을 위해
- Java에서 컬렉션 프레임워크를 사용해서 데이터를 다루는 법에 대해 배워보자
// hm = HashMap<String, String>
Set<Entry<String, String>> s = hm.entrySet();
Iterator<Entry<String, String>> it = s.iterator();
while(it.hasNext()){
Map.Entry<String, String> m = (Map.Entry<String, String>)it.next();
String value = m.getValue();
...
}
1. Java Collection Framework
- 자료구조 종류의 형태들을 자바 클래스로 구현한 모음집이라고 보면 된다
- Tip ) 컬렉션 프레임워크에 저장할 수 있는 데이터는 오로지
객체(Object) 뿐이다
- 즉,
primitive 타입은 Wrapper타입으로 변환하여 객체형으로 Boxing하여 저장하여야 한다
- 또한, 객체를 담는다는 것은 곧 주소값을 담는다는 뜻이니,
null도 저장이 가능하다
2. JCF의 종류
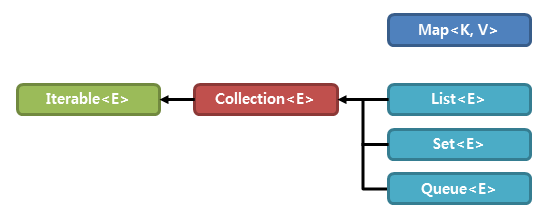
- 크게
Collection 인터페이스와 Map 인터페이스로 나뉜다
Collection인터페이스는 다시 List 인터페이스와 Set 인터페이스로 나뉘고Map 인터페이스는 두 개의 데이터를 묶어 한 쌍으로 다루는 특징으로 Collection 인터페이스와 따로 분리되어 있다
- Tip) 대부분의 컬렉션 클래스들은
List, Set, Map 중 하나를 구현하고 있으며, 구현한 인터페이스의 이름이 클래스 이름에 포함되는 특징이 있다
- ex)
ArrayList, HashSet, HashMap 등
- 예외로
Vector, Stack, Hashtable, Properties 등의 클래스들은 컬렉션 프레임워크가 만들어지기 이전부터 존재하던 것이어서 JCF의 명명법을 따르지 않고 있다
- 이러한 기존의 컬렉션 클래스들은 호환을 위해 남겨진 것이므로 가급적 사용하지 않는 것이 좋다
2-1. JCF 주요 인터페이스의 간략한 특징
| 인터페이스 |
설명 |
구현 클래스 |
| List |
순서가 있는 데이터의 집합, 데이터의 중복을 허용함 |
Vector, ArrayList, LinkedList, Stack, Queue |
| Set |
순서가 없는 데이터의 집합, 데이터의 중복을 허용하지 않음 |
HashSet, TreeSet |
| Map<K, V> |
키와 값의 한 쌍으로 이루어지는 데이터의 집합, 순서가 없음. 키는 중복을 허용하지 않으나, 값은 중복될 수 있음 |
HashMap, TreeMap, Hashtable, Properties |
3. Iterable 인터페이스
- 컬렉션 인터페이스들의 가장 최상위 인터페이스
- 이 인터페이스로 관리되는
Iterator 객체로 컬렉션으로 구현된 자료들을 순회(순차적으로 접근)할 때 사용할 수 있다
- 이 Iterator객체를 통해 데이터 집합을 순회할 경우 장점은 다음과 같다
- 컬렉션마다 구조가 다르고 요소에 접근하는 방법이 상이한데, 이를 사용하면 요소에 접근하는 방식을 공통화할 수 있다
| 메서드 |
설명 |
default void forEach(Consumer<? super T> action) |
Iterable 모든 요소가 처리되거나 작업에서 예외가 발생할 때까지 각 요소에 대해 지정된 작업을 수행 |
Iterator iterator() |
이터레이터 객체를 반환 |
default Spliterator splierator() |
파이프라이닝 관련 메소드 |
- Tip ) 참고로, Map은 interable 인터페이스를 상속받지 않기 때문에
iterator()와 spliterator()는 Map 컬렉션에 구현되어 있지 않다
- 따라서, 직접적으로 Map 컬렉션을 순회할수는 없고,
Stream(스트림)을 사용하거나
- 간접적으로 키를 Collection으로 반환하여 루프문으로 순회하는 방식으로 이용한다
4. Collection 인터페이스
- List, Set, Queue가 상속되는 실질적인 최상위 컬렉션 타입
- 업캐스팅으로 다양한 종류의 컬렉션 자료형을 받아, 자료를 삽입하거나 삭제, 탐색할 수 있다 (= 다형성)
Collection<Number> col1 = new ArrayList<>();
col1.add(1);
Collection<Number> col2 = new HashSet<>();
Collection<Number> col3 = new LinkedList<>();
5. Set 인터페이스
- 데이터의 중복을 허용하지 않고 순서를 유지하지 않는 데이터의 집합 리스트 (집합적인 저장공간)
- 순서 자체가 없으므로, 인덱스로 객체를 검색해 가져오는
get(index)메서드도 존재하지 않음
- 중복 저장이 불가능한데, 심지어 null값도 하나만 저장할 수 있다
| 메서드 |
설명 |
| boolean add(E e) |
주어진 객체를 저장 후 성공적이면 true, 중복 객체면 false 리턴 |
| boolean contains(Object o) |
주어진 객체가 저장되어있는지 여부를 리턴 |
| Iterator iterator() |
저장된 객체를 한번씩 가져오는 반복자를 리턴 |
| isEmpty() |
컬렉션이 비어있는지 조사 |
| int Size() |
저장되어 있는 전체 객체수를 리턴 |
| void clear() |
저장된 모든 객체를 삭제 |
| boolean remove(Object o) |
주어진 객체를 삭제 |
5-1. HashSet 클래스
- 배열과 연결 노드를 결합한 자료구조 형태
- 가장 빠른 임의 검색 접근 속도를 가진다
- 추가, 삭제, 검색, 접근성이 모두 뛰어나다
- 대신 순서를 전혀 예측할 수 없다
5-2. LinkedHashSet 클래스
- 순서를 가지는 Set 자료
- 추가된 순서 또는 가장 최근에 접근한 순서대로 접근 가능
- 만일 중복을 제거하는 동시에 저장한 순서를 유지하고 싶다면, HashSet 대신 LinkedHashSet을 사용하면 됨
5-3. TreeSet 클래스
- 이진 검색트리 (binary search tree) 자료구조의 형태로 데이터를 저장
- 중복을 허용하지 않고, 순서를 가지지 않음
- 대신 데이터를 정렬하여 저장하고 있다는 특징
- 정렬, 검색, 범위 검색에 높은 성능
5-4. EnumSet 추상 클래스
Enum 클래스와 함께 동작하는 Set 컬렉션- 중복되지 않은 상수 그룹을 나타내는데 사용됨
- 산술 비트 연산을 사용하여 구현되어, HashSet보다 훨씬 빠르고 적은 메모리를 사용한다
- 단, enum 타입의 요소값만 저장할 수 있고, 모든 요소들은 동일한 enum 객체에 소속되어야 한다
- EnumSet은 추상클래스로, 이를 상속한
RegularEnumSet 혹은 JumboEnumSet 객체를 사용하게 된다
6. Map 인터페이스
- 키(key)와 값(value)의 쌍으로 연관지어 이루어진 데이터의 집합
- 값(value)은 중복되어 저장될 수 있지만, 키(key)는 해당 map에서 고유해야함
- 만일 기존에 저장된 데이터와 중복된 키와 값을 저장하면, 기존의 값을 없어지고 마지막에 저장한 값이 남는다
- 저장 순서 유지 안됨
| 추상메서드 |
설명 |
| void clear() |
Map의 모든 객체를 삭제 |
| boolean containsKey(Object key) |
지정된 key객체와 일치하는 객체가 있는지 확인 |
| boolean containsValue(Object value) |
지정된 value객체와 일치하는 객체가 있는지 확인 |
| Set entrySet() |
Map에 저장된 key-value쌍을 Map.Entry 타입의 객체로 저장한 Set을 반환 |
| boolean equals(Object o) |
동일한 Map인지 비교 |
| Object get(Object key) |
지정한 key 객체에 대응하는 value 객체를 반환 |
| int hashCode() |
해시코드를 반환 |
| boolean isEmpty() |
Map이 비어있는지 확인 |
| Set keySet() |
Map에 저장된 모든 key 객체를 반환 |
| Object put(Object key, Object value) |
Map에 key 객체와 value 객체를 연결(mapping)하여 저장 |
| void putAll(Map t) |
지정된 Map의 모든 key-value쌍을 추가 |
| Object remove(Object key) |
지정한 key객체와 일치하는 key-value 객체를 삭제 |
| int size() |
Map에 저장된 key-value 쌍의 개수를 반환 |
| Collection values() |
Map에 저장된 모든 value 객체를 반환 |
tip :
Map 인터페이스의 메소드를 보면, Key값을 반환할 때는 Set 인터페이스 타입으로 반환하고, Value값을 반환할 때는 Collection 타입으로 반환하는 것을 볼 수 있다.
이는 Map 인터페이스에서 값(value)은 중복을 허용하기 때문에 Collection 타입으로 반환하고, 키(key)는 중복을 허용하지 않기 때문에 Set 타입으로 반환하는 것이다
6-1. Map.Entry 인터페이스
Map.Entry 인터페이스는 Map 인터페이스 안에 있는 내부 인터페이스이다- Map에 저장되는 key-value 쌍의
Node 내부 클래스가 이를 구현하고 있다
- Map 자료구조를 보다 객체지향적인 설계를 하도록 유도하기 위함
| 메서드 |
설명 |
| boolean equals(Object o) |
동일한 Entry인지 비교 |
| Object getKey() |
Entry의 key 객체를 반환 |
| Object getValue() |
Entry의 value 객체를 반환 |
| int hashCode() |
Entry의 해시코드 반환 |
| Object setValue(Object value) |
Entry의 value 객체를 지정된 객체로 바꿈 |
Map<String, Integer> map = new HashMap<>();
map.put("a", 1);
map.put("b", 2);
map.put("c", 3);
// Map.Entry 인터페이스를 구현하고 있는 Key-Value 쌍을 가지고 있는 HashMap의 Node 객체들의 Set 집합을 반환
Set<Map.Entry<String, Integer>> entry = map.entrySet();
System.out.println(entry); // [1=a, 2=b, 3=c]
// Set을 순회하면서 Map.Entry를 구현한 Node 객체에서 key와 value를 얻어 출력
for (Map.Entry<String, Integer> e : entry) {
System.out.printf("{ %s : %d }\n", e.getKey(), e.getValue());
}
6-2. HashMap 클래스
- HashTable을 보완한 컬렉션
- 배열과 연결이 결합된 Hashing 형태
- 키(key) 와 값(value)을 묶어 하나의 데이터로 저장
- 중복을 허용하지 않고, 순서를 보장하지 않음
- 키과 값에 null이 허용
- 추가, 삭제, 검색, 접근성이 모두 뛰어나다
- HashMap은 비동기로 작동하기 때문에 멀티쓰레드 환경에서는 어울리지 않는다 (대신
ConcurrentHashMap 사용)
Map<String, String> hashMap = new HashMap<>();
hashMap.put("love", "사랑");
hashMap.put("apple", "사과");
hashMap.put("baby", "아기");
hashMap.get("apple"); // "사과"
// hashmap의 key값들을 set 집합으로 반환하고 순회
for(String key : hashMap.keySet()) {
System.out.println(key + " => " + hashMap.get(key));
}
/*
love => 사랑
apple => 사과
baby => 아기
*/
6-3. LinkedHashMap 클래스
- HashMap을 상속하기 때문에 흡사하나, Entry들이 연결리스트를 구성하여 데이터의 순서를 보장
- 일반적으로 Map 자료구조는 순서를 가지지 않으나, LinkedHashMap은 들어온 순서대로 순서를 가짐
6-4. TreeMap 클래스
- 이진 검색 트리의 형태로 키와 값의 쌍으로 이루어진 데이터를 저장(TreeSet과 같은 원리)
- TreeMap은 SortedMap 인터페이스를 구현하고 있어, Key값을 기준으로 정렬되는 특징
- 정렬된 순서로 키/값 쌍을 저장하므로, 빠른 검색(특히 범위검색)이 가능
- 단 저장하는 동시에 정렬을 행하므로 저장시간이 다소 걸림
- 정렬순서 : 숫자 -> 알파벳 대문자 -> 알파벳 소문자 -> 한글 순
6-5. HashTable 클래스
- Key를 특정 해시 함수를 통해 해싱한 후, 나온 결과를 배열의 인덱스로 사용해 Value를 찾는 방식으로 동작
- HashMap 보다는 느리나 동기화가 기본적으로 지원됨
- 키와 값으로 null 허용X
6-6. Properties 클래스
- Properties(String, String) 의 형태로 저장하는 단순화된 key-value 컬렉션
- 주로 애플리케이션 환경설정과 관련된 속성 파일인 .properties 설정하는데 사용
7. 결국, 아래 코드의 해석은
// hm = HashMap<String, String>
// 1. hashMap의 데이터를 키-값이 String형인 엔트리(Map.Entry타입)객체를 담은 Set형식으로 만들고
// (Set : 중복허용X, 순서유지X)
Set<Entry<String, String>> s = hm.entrySet();
// 2. Entry 객체를 하나씩 가져오는 반복자(Iterator)에 담고
Iterator<Entry<String, String>> it = s.iterator();
// 3. hasNext()를 써서 다음요소가 있으면 가져오고
while(it.hasNext()){
Map.Entry<String, String> m = (Map.Entry<String, String>)it.next();
// 4. Entry의 value객체를 value변수에 담는다
String value = m.getValue();
...
}
즉, 간략히 해석하자면 hashMap에 있는 데이터들을 쭉 꺼내어 value값을 담는 코드!라고 볼 수 있다
7-1. Iterator 의 장점
- 컬렉션에서 요소를 제어하는 기능을 수행
next(), previous()를 사용하여 컬렉션의 앞뒤로 이동할 수 있음hasNext()를 써서 더 많은 요소가 있는지 확인할 수 있음- 인덱스가 없는 Set과 같은 자료구조의 경우, for문을 사용할 수 없고 for-each문에서도 문제가 발생할 수 있다 (ex. ConcurrentModificationException) 따라서 이런 경우 Iterator를 사용할 수 있다
참고 사이트